The mle-logging Package
![]()
Experiment logging made easy 📖
Each Python-based experiment is assumed to use a custom logger: The MLELogger. This enables the standardization needed to automatically aggregate multiple random runs and to log performance across hyperparameter searches. For a quickstart checkout the notebook blog 🚀
The API 🎮
from mle_logging import MLELogger
# Instantiate logging to experiment_dir
log = MLELogger(time_to_track=['num_updates', 'num_epochs'],
what_to_track=['train_loss', 'test_loss'],
experiment_dir="experiment_dir/",
model_type='torch')
time_tic = {'num_updates': 10, 'num_epochs': 1}
stats_tic = {'train_loss': 0.1234, 'test_loss': 0.1235}
# Update the log with collected data & save it to .hdf5
log.update(time_tic, stats_tic)
log.save()
You can also log model checkpoints, matplotlib figures and other .pkl compatible objects.
# Save a model (torch, tensorflow, sklearn, jax, numpy)
import torchvision.models as models
model = models.resnet18()
log.save_model(model)
# Save a matplotlib figure as .png
fig, ax = plt.subplots()
log.save_plot(fig)
# You can also save (somewhat) arbitrary objects .pkl
some_dict = {"hi" : "there"}
log.save_extra(some_dict)
Or do everything in a single line...
log.update(time_tic, stats_tic, model, fig, extra, save=True)
File Structure & Re-Loading 📚
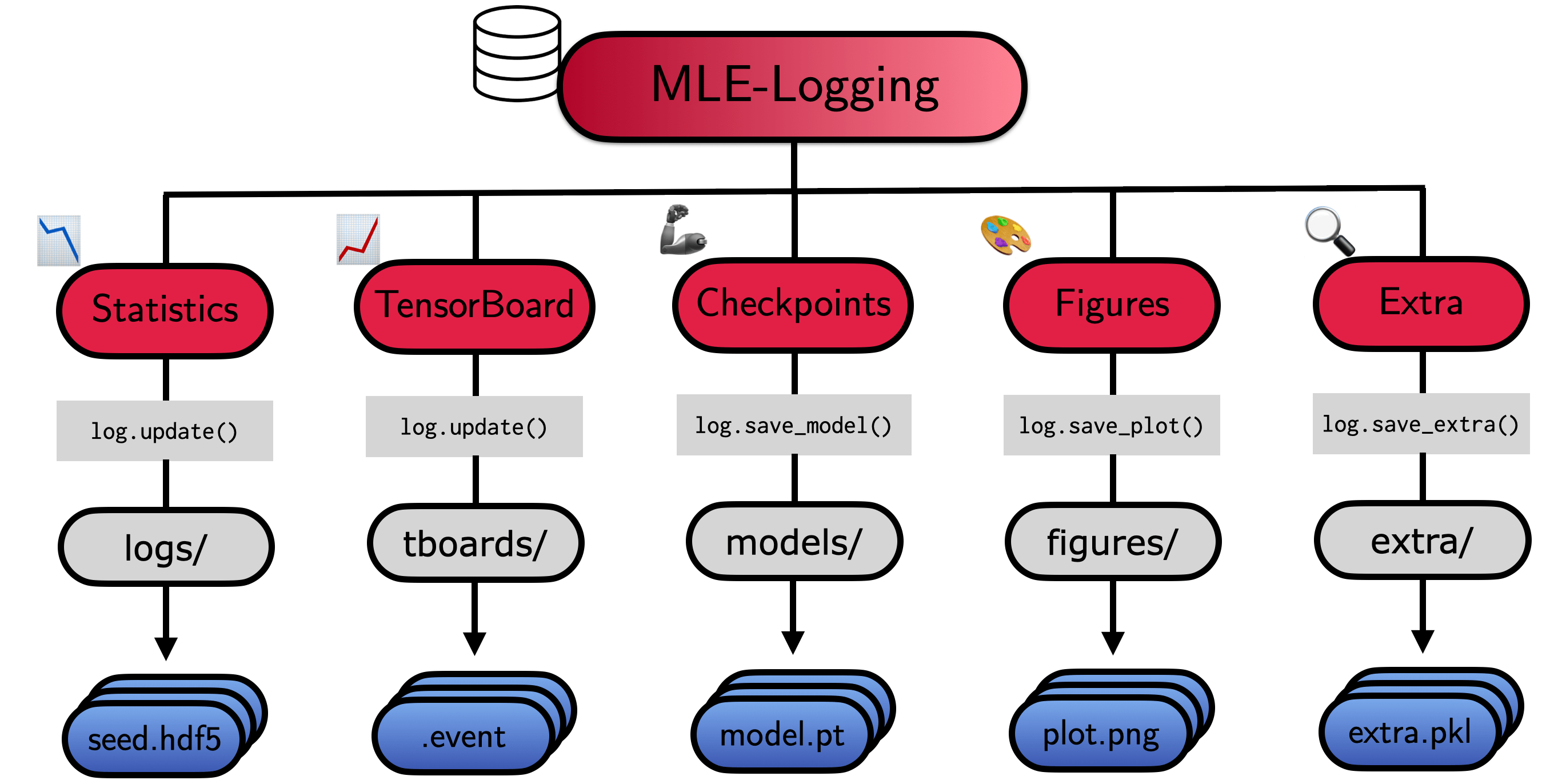
The MLELogger will create a nested directory, which looks as follows:
experiment_dir
├── extra: Stores saved .pkl object files
├── figures: Stores saved .png figures
├── logs: Stores .hdf5 log files (meta, stats, time)
├── models: Stores different model checkpoints
├── init: Stores initial checkpoint
├── final: Stores most recent checkpoint
├── every_k: Stores every k-th checkpoint provided in update
├── top_k: Stores portfolio of top-k checkpoints based on performance
├── tboards: Stores tensorboards for model checkpointing
├── <config_name>.json: Copy of configuration file (if provided)
For visualization and post-processing load the results via
from mle_logging import load_log
log_out = load_log("experiment_dir/")
# The results can be accessed via meta, stats and time keys
# >>> log_out.meta.keys()
# odict_keys(['experiment_dir', 'extra_storage_paths', 'fig_storage_paths', 'log_paths', 'model_ckpt', 'model_type'])
# >>> log_out.stats.keys()
# odict_keys(['test_loss', 'train_loss'])
# >>> log_out.time.keys()
# odict_keys(['time', 'num_epochs', 'num_updates', 'time_elapsed'])
If an experiment was aborted, you can reload and continue the previous run via the reload=True option:
log = MLELogger(time_to_track=['num_updates', 'num_epochs'],
what_to_track=['train_loss', 'test_loss'],
experiment_dir="experiment_dir/",
model_type='torch',
reload=True)
Installation ⏳
A PyPI installation is available via:
pip install mle-logging
Alternatively, you can clone this repository and afterwards 'manually' install it:
git clone https://github.com/RobertTLange/mle-logging.git
cd mle-logging
pip install -e .
Advanced Options 🚴
Merging Multiple Logs 👫
Merging Multiple Random Seeds 🌱 + 🌱
from mle_logging import merge_seed_logs
merge_seed_logs("multi_seed.hdf", "experiment_dir/")
log_out = load_log("experiment_dir/")
# >>> log.eval_ids
# ['seed_1', 'seed_2']
Merging Multiple Configurations 🔖 + 🔖
from mle_logging import merge_config_logs, load_meta_log
merge_config_logs(experiment_dir="experiment_dir/",
all_run_ids=["config_1", "config_2"])
meta_log = load_meta_log("multi_config_dir/meta_log.hdf5")
# >>> log.eval_ids
# ['config_2', 'config_1']
# >>> meta_log.config_1.stats.test_loss.keys()
# odict_keys(['mean', 'std', 'p50', 'p10', 'p25', 'p75', 'p90']))
Plotting of Logs 🧑🎨
meta_log = load_meta_log("multi_config_dir/meta_log.hdf5")
meta_log.plot("train_loss", "num_updates")
Storing Checkpoint Portfolios 📂
Logging every k-th checkpoint update ❗ ⏩ ... ⏩ ❗
# Save every second checkpoint provided in log.update (stored in models/every_k)
log = MLELogger(time_to_track=['num_updates', 'num_epochs'],
what_to_track=['train_loss', 'test_loss'],
experiment_dir='every_k_dir/',
model_type='torch',
ckpt_time_to_track='num_updates',
save_every_k_ckpt=2)
Logging top-k checkpoints based on metric 🔱
# Save top-3 checkpoints provided in log.update (stored in models/top_k)
# Based on minimizing the test_loss metric
log = MLELogger(time_to_track=['num_updates', 'num_epochs'],
what_to_track=['train_loss', 'test_loss'],
experiment_dir="top_k_dir/",
model_type='torch',
ckpt_time_to_track='num_updates',
save_top_k_ckpt=3,
top_k_metric_name="test_loss",
top_k_minimize_metric=True)